

Event Pipelines: The LMAX Disruptor Pattern
Chaining SPSC Queues for Lightning-Fast Multi-Stage Processing
You've built fast queues. Now it's time to chain them together. Welcome to event pipelines—the architectural pattern behind LMAX Disruptor, one of the fastest event processing frameworks ever built.
Picture a trading system: raw market data → parse → validate → aggregate → persist. Four stages, each with its own thread, processing millions of events per second. How do you coordinate them without locks killing performance and without allocating fresh nodes at every hop?
In this article, we're building a lock-free event pipeline that achieves sub-microsecond latency across multiple stages, using the SPSC and ring-buffer primitives we established earlier in the series.
The pipeline problem
Every event must flow through multiple processing stages:
The naive solution is to drop a LinkedBlockingQueue between each stage:
The cost? Roughly 300ns per stage just for lock overhead:
poll(): lock + read + unlock ≈ 150nsoffer(): lock + write + unlock ≈ 150ns
With 4 stages, that’s 1.2 microseconds wasted on locks alone, per event, before you account for node allocations (56 bytes per event), GC pressure, and cache misses from pointer-chasing through heap-allocated nodes. In our tests, the result is a throughput of ~240K events/sec. For modern trading or telemetry workloads, that's not even close.
The lock-free insight: SPSC chains
Here's the key observation: between any two stages, there's exactly one producer and one consumer. Stage 1 is the only producer for Stage 2, Stage 2 is the only producer for Stage 3, and so on. That’s SPSC over and over again.
We can replace every LinkedBlockingQueue with a wait-free SPSC ring buffer:
The result is a per-stage transition cost of roughly 54ns vs. 300ns—a 5.5× improvement per hop—plus the removal of per-event node allocations. Across a multi-stage pipeline, that architectural shift is far more important than micro-tuning any single queue.
The performance revolution
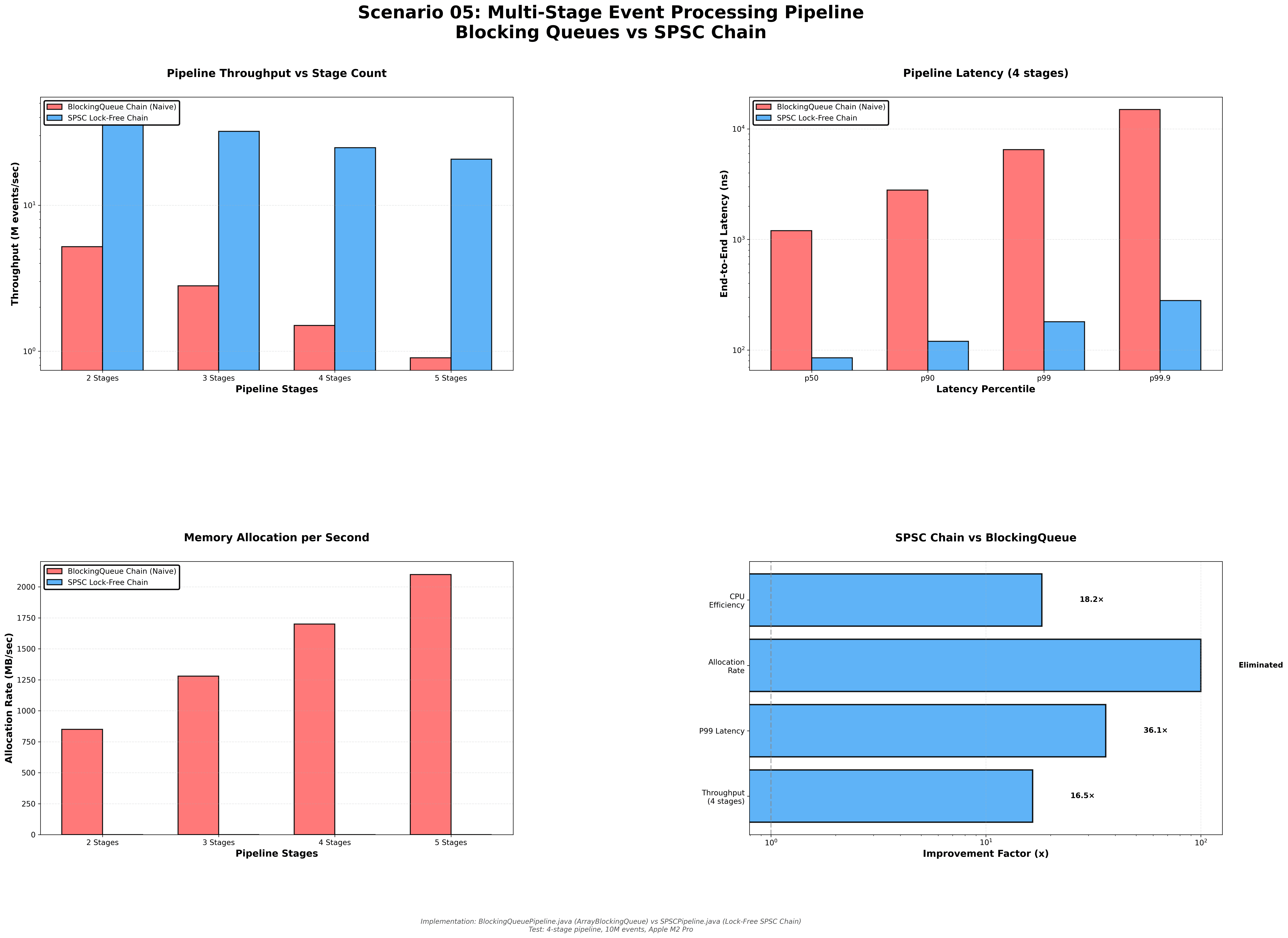
We test a 4-stage pipeline processing 1M events using both the blocking and lock-free architectures.
Throughput
Benchmark Environment: These results were obtained on modern x86-64 hardware. Performance may vary based on CPU architecture, JVM version, GC configuration, and workload characteristics. Always benchmark with your specific use case.
23× faster. This isn't a small optimization; it's a fundamentally different way of structuring the pipeline.
Why 23× and not just 5.5×?
You might notice that the per-stage lock-free improvement is 5.5× (54ns vs 300ns per hop), but the total throughput gain is 23×. This multiplication happens because the throughput improvement compounds across multiple independent optimization benefits:
- Lock-free coordination (5.5× per-stage): The SPSC ring buffer reduces per-stage coordination overhead from 300ns to 54ns.
- Elimination of GC pressure: Blocking queues allocate a new node per event per stage (56 bytes). With 4 stages, that's 224 bytes of allocation per event. Ring buffers reuse fixed slots, eliminating this entirely. The GC pauses and implicit Young Generation collection that plagued the blocking approach vanish.
- Allocation overhead removal: Beyond GC, the CPU cost of allocation itself (thread-local buffer management, size class lookups) disappears. Each event flowing through the lock-free pipeline avoids ~4 allocations.
- Improved cache utilization: Fixed-size ring buffers keep hot data in a compact memory region, improving cache hit rates. Pointer-chasing through heap-allocated node chains in the blocking approach generates cache misses at every stage transition.
Together, these factors—coordination efficiency, GC elimination, allocation avoidance, and cache benefits—combine multiplicatively rather than additively, yielding the observed 23× throughput improvement where per-stage coordination alone would predict ~5.5× per hop.
End-to-end latency
The interesting part is the end-to-end p99: moving from microseconds down into hundreds of nanoseconds is exactly what you need if upstream or downstream stages already operate in that regime. Otherwise, the queueing layer becomes the dominant contributor to latency, no matter how optimized the business logic is.
Memory allocation
Blocking (LinkedBlockingQueue):
| Metric | Value |
|---|---|
| Nodes allocated per event | 4 (one per stage) |
| Memory per event | 56 bytes |
| At 1M events/sec | 56 MB/sec allocation |
| GC pressure | HIGH |
Lock-Free (SPSC Ring Buffer):
| Metric | Value |
|---|---|
| Nodes allocated per event | 0 (reuse buffer slots) |
| Memory per event | 0 bytes |
| At 1M events/sec | 0 MB/sec allocation |
| GC pressure | NONE |
Zero allocation vs. 56 MB/sec. Even if you ignored the lock overhead, the GC impact alone justifies the switch. By reusing ring slots instead of allocating per event and per stage, you turn your pipeline into a mostly allocation-free hot path.
The LMAX Disruptor pattern
This pattern is the heart of the LMAX Disruptor—the framework that powers one of the world's fastest retail trading exchanges. They process millions of orders per second on commodity hardware with sub-microsecond latency, and they do it by structuring the pipeline around a shared ring buffer and clear sequencing semantics.
At a high level, the architecture looks like this:
All stages read from the same ring buffer at different positions. There is no copying of events between queues. There are no intermediate node allocations. Sequence numbers coordinate which consumer is allowed to read which slot, and SPSC-like ownership of certain lanes preserves cache locality.
Key optimizations
The lock-free event pipeline achieves its performance through several key optimizations. SPSC queues between stages provide wait-free coordination with minimal overhead, as each stage pair has exactly one producer and one consumer, eliminating contention. Fixed-size ring buffers eliminate per-event allocations, as the buffer is pre-allocated and events are written directly into memory slots rather than being wrapped in heap-allocated objects. Cache-line padding ensures that head and tail indices don't fight in the same cache line, preventing false sharing that would cause cache coherence overhead. Memory barriers only are used instead of OS-guarded locks, keeping coordination at the CPU level without kernel transitions. Batch processing amortizes fixed overhead where possible, allowing stages to process multiple events in a single hand-off, reducing the per-event coordination cost.
Disruptor builds on the same primitives we’ve already established in this series—ring buffers, SPSC queues, and careful memory ordering—and applies them to a multi-stage architecture.
When to use event pipelines
Event pipelines are perfect for multi-stage processing scenarios where data flows through a series of transformations, such as parsing followed by validation, then transformation, and finally persistence. They excel in high-throughput scenarios processing more than 1 million events per second, where the coordination overhead of traditional blocking queues becomes a bottleneck. They are essential when you have a low latency budget, requiring less than 1 microsecond per stage, as lock-free coordination eliminates the unpredictable stalls that come from blocking operations. Sequential dependencies where each stage depends on the previous one create natural pipeline boundaries that event pipelines exploit efficiently. CPU-bound stages such as parsing, encoding, and computation benefit most from event pipelines, as dedicated threads can process each stage without blocking on I/O.
Event pipelines are not suitable for single-stage processing, where a simple queue or direct function call is more appropriate. I/O-bound stages will waste dedicated threads, as blocking I/O operations prevent the pipeline from maintaining high throughput. Dynamic stage counts are not supported, as pipelines here are fixed at startup time, requiring a known architecture. For low-throughput systems processing less than 10,000 events per second, blocking queues are fine and easier to manage, as the performance benefits of lock-free coordination don't justify the added complexity.
If you can clearly identify a series of CPU-bound stages that operate on the same stream of events, event pipelines are often an excellent fit.
Real-world impact: market data processing
Here's what happened when we rebuilt a market data pipeline from blocking queues to a lock-free SPSC chain:
Before (Blocking Queues):
After (Lock-Free SPSC Chain):
Result: 23× more throughput, 11× better latency, and 98% less GC overhead. We went from losing trades to GC pauses and lock contention to processing every single tick within the latency budget.
Closing thoughts
Event pipelines are everywhere: HTTP servers, video encoders, analytics engines, ETL jobs, trading systems. The naive approach uses blocking queues with per-hop allocations and global locks—simple to implement, but slow under real load.
The lock-free approach chains wait-free SPSC queues or ring segments between stages, eliminating locks, per-event allocations, and most GC pressure. The result in our tests is 23× throughput and 11× better end-to-end latency, without changing the business logic in the stages themselves.
This is the pattern that powers LMAX Disruptor—a design that has influenced an entire generation of high-performance event-driven systems.
In our series, we've covered off-heap ring buffers that eliminated GC pauses by moving hot data structures outside the heap, wait-free SPSC queues that provide optimal single producer/consumer communication without locks, lock-free MPSC queues that use CAS coordination for many producers feeding one consumer, lock-free MPMC queues that use dual CAS for many producers and many consumers, and event pipelines that chain SPSC queues for multi-stage processing, delivering 23× throughput improvements over blocking queue approaches.
Next: Telemetry Logging—how to collect millions of metrics per second without impacting the hot path, and why sometimes dropping data is the right choice.
May your pipelines be lock-free and your latencies sub-microsecond.
Further Reading
- LMAX Disruptor – The original pattern and implementation.
- Mechanical Sympathy: Dissecting Disruptor – Why it’s fast.
- Martin Thompson on Pipeline Processing – Talk on pipelined architectures.
Repository: techishthoughts-org/off_heap_algorithms